原文:Deep Count: Fruit Counting Based on Deep Simulated Learning
摘要
近年来,基于深度学习的计算机视觉研究取得了重大进展。这些任务的成功很大程度上依赖于大量的训练样本。对训练样本进行标记是一个挺费劲的过程。在文中,我们提出了一种基于模拟深度卷积神经网络的产量估算的方法。了解果树、花卉和树木的确切数量有助于农民更好地做出关于栽培实践、植物病害预防和收获劳动力规模的决定。目前人工估算果实或花卉的产量估算方法是一个费时费力的过程,在大面积的生产中是不实用的。基于机器人农业的自动产量估计在这方面提供了可行的解决方案。该网络由合成数据进行训练,并在真实数据上进行测试。为了在多个尺度上捕获特征,我们使用了一个改进版本的Inception-RESNET架构。即使在阴影下、叶子、树枝遮挡,或有一定程度的重叠,我们的算法计数依然表现良好。实验结果表明,实际图像的平均测试精度为91%,合成图像的测试精度为93%。
1. 简介
近年来,基于深度学习的计算机视觉研究取得了巨大的进步。各种基于视觉的任务,如物体识别、分类和计数,可以实现高精度。这些高级任务的成功很大程度上依赖于大量的训练样本。训练样本的标注是一个费时费力的过程。而生成用于训练的合成数据则提供另一种解决的方案。本研究的目的之一是通过创建用于训练的合成数据集来减少对对象计数问题的训练样本的标记开销。本研究实现了一种基于深度模拟学习的快速产量估计的方法。准确的产量预测不仅有助于农民提高作物品质,还有助于通过更好地决定作物收获的强度和所需的劳动来降低经营成本。
计算机视觉算法在计算果实产量时面临着各种各样的挑战,如光照方差、叶片遮挡、果实间重叠的程度以及阴影下果实的尺度变化等。为了应对这些挑战,在本研究中,我们开发了一种新的深度学习架构,在不检测对象的情况下对对象进行计数。我们的方法从整个图像的浏览中显式地估计对象的数量。这样,它减少了对象检测和定位的开销。我们的网络由多个卷积和池化层组成,除此之外还包括改进的Inception- resnet。改进后的Inception-resnet版本可以帮助我们捕捉多尺度的特征。我们的方法的框架如图1所示。
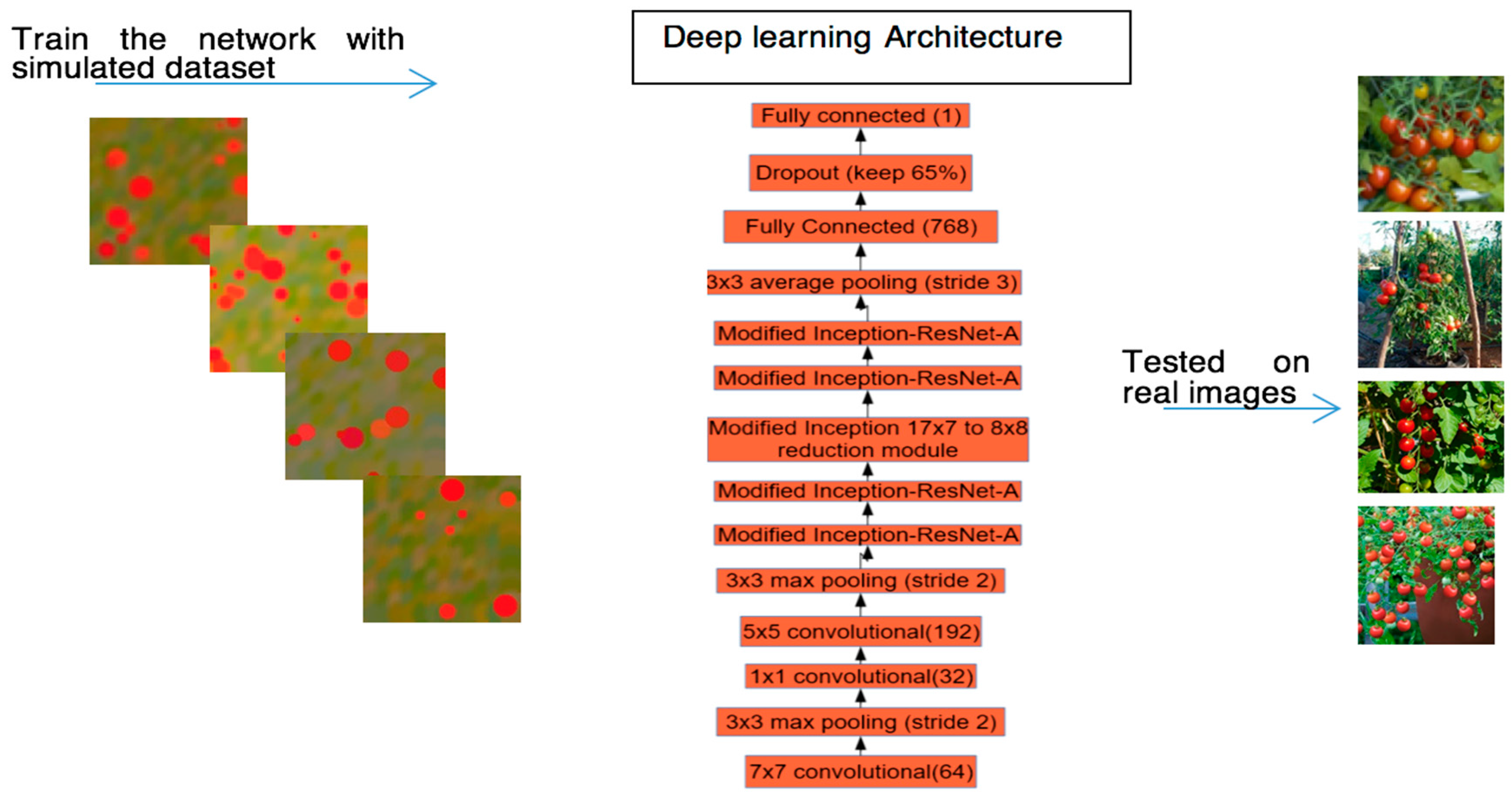 图1 我们的研究框架
本方法的主要优点是,不再需要用成千上万的带标注的真实图像去训练了,使用合成图像去训练网络并在真实图像上进行测试,就可以在真实图像上达到91%的精度了。即使在图像中存在光照不均的情况,本文的方法也表现良好。
以下是这项工作的贡献:
(1)提出了一种基于卷积神经网络的果实计数的新型深度学习架构,并对Inception-resnet进行了改进。
(2)开发了一种基于模拟的学习方法,该方法用模拟数据进行训练,用真实数据进行测试。
(3)该方法对遮挡、光照变化和尺度变化都是很有效的。
(4)该算法的工作速度是1秒以内,这对于实时性要求高的应用是非常有用的。
图1 我们的研究框架
本方法的主要优点是,不再需要用成千上万的带标注的真实图像去训练了,使用合成图像去训练网络并在真实图像上进行测试,就可以在真实图像上达到91%的精度了。即使在图像中存在光照不均的情况,本文的方法也表现良好。
以下是这项工作的贡献:
(1)提出了一种基于卷积神经网络的果实计数的新型深度学习架构,并对Inception-resnet进行了改进。
(2)开发了一种基于模拟的学习方法,该方法用模拟数据进行训练,用真实数据进行测试。
(3)该方法对遮挡、光照变化和尺度变化都是很有效的。
(4)该算法的工作速度是1秒以内,这对于实时性要求高的应用是非常有用的。
2. 相关工作
在典型的图像分类过程中,任务是指定一个对象的存在与否,但是计算问题需要说明在场景中有多少个对象的实例。计数问题出现在一些现实世界的应用中,如显微镜图像的细胞计数[13],空中图像的野生动物计数[14],鱼类计数[15],监测系统中的人群监测[16]。Kim等人提出的方法是利用一个固定的单摄像机来检测和跟踪移动的人。后来,Lempitsky等人提出了一种新的可视对象计数任务的监督学习框架,该框架基于学习过程中的中距优化损失。最近,Giuffrida等人提出了一种基于学习的方法来计算玫瑰座(模型)植物的叶子数量。他们使用一个监督的回归模型来关联基于图像的描述符,这些描述符是在无监督的情况下学习到叶子计数的。目前基于工人手工计算或花卉的产量估算的做法是非常耗时耗力的,对于大的领域是不实用的。基于机器人农业的产量自动估计提供了一种可行的解决方案。一种被广泛采用的自动产量估计方法是使用计算机视觉算法对进行计数或计算图像上的花朵密度[20,21,22,23,24,25,26]。基于计算机视觉的作物产量估计方法大致可分为两类:(1)基于区域的方法和(2)基于计数的方法。在文献中,有大量的工作处理基于区域的方法[20,21,22,23,24,25,26]。Wang等[20]为苹果园开发了一种立体摄像机自动作物产量估算系统。他们在夜间拍摄图像,以减少白天不可预知的自然光照。Li等人开发了一种基于区域语义图像分割的现场棉花检测系统。Lu等人开发了基于区域的联合作物和玉米穗分割颜色建模。尽管对基于区域的方法有广泛的关注,但对基于计数的收益估计方法的关注却很少[27,28]。Linker等[27]用彩色图像来估计在自然光照下在果园中获得的苹果数。缺点是直接光照和色彩饱和度,因为有大量的假阳性被观察到。Tabb等人开发了一种利用背景建模从视频中分割苹果的方法。 最近,基于深度学习的对象计数方法越来越流行。Segui等人与CNN探讨了计算感兴趣的概念出现次数的任务。Xie等人开发了基于卷积回归网络的显微镜细胞计数框架。Zhang等人开发了基于深度卷积神经网络的跨场景人群计数框架。French et al.[29]也在一段渔业监控视频中探索了CNN对鱼的计数。一些作者探索了/植物检测和识别的深度学习方法[30,31,32,33,34]。据我们所知,没有关于基于深度模拟学习的计数的论文;所有基于深度学习的计数方法都依赖于对象检测,然后对检测到的实例进行计数。我们的方法通过对整个图像的浏览来明确地估计对象的数量。通过这种方式,它减少了对象检测和定位的开销,并明确地学会了计数。此外,前面提到的技术依赖于大量的标记数据。在培训样本上贴标签的花费在时间和金钱上都很昂贵。在这里,我们生成合成数据,以减少为对象计数问题标记训练样本的开销。我们的方法虽然经过合成数据的训练,但在实际数据上却表现得很好。
3. 研究方法
3.1合成图像生成
深度学习需要大量的数据集,这些数据集收集和标注都非常耗时。为了解决这个问题,我们生成了合成数据来训练我们的网络,然后在真实图像上测试训练参数。合成图像如下所示,创建一个大小为128×128像素的空白图像,然后用绿色和棕色的圆形填充整个图像以模拟背景和西红柿植株,后者被高斯滤波器模糊。为了在图像中创建大小不一的西红柿,在图像上以随机的位置绘制几个随机大小的圆。生成了24000幅图像作为训练样板集,生成了2400幅图像作为测试样本集。图2展示了生成用于训练网络的合成图像的过程。合成的西红柿图像随着尺寸、比例和光照的变化而产生一定程度的重叠,以便模拟西红柿图像中可能出现的真实复杂场景。
 图2 合成图像的生成
图2 合成图像的生成
3.2卷积神经网络
CNN是最著名的深度学习方法之一;它包括不同的卷积和池化(子采样)层,类似于人类的视觉系统。通常来说,图像数据被输入到CNN的输入层,并产生与对象类相关的具有相当明显特征的向量作为输出层。在输入层和输出层之间,隐藏层以一系列卷积和池化层的形式出现,然后是全连接层。网络的训练是基于预测输出和真实标签并在前向和后向传播阶段进行的。在反向传播阶段,根据损失成本计算各参数的梯度。所有参数将根据梯度进行更新,并为下一个前向传播进行更新。经过充分的前向、后向传播的迭代之后,网络学习可以停止。
3.3Inception的体系结构
当一个卷积层试图学习同时在三维空间中使用两个空间维度和一个通道维度进行过滤时,Inception模型使这个过程变得更容易,因此从经验上看,它似乎能够以更少的参数学习更丰富的表示。Inception模型将独立研究跨通道相关性和空间相关性。Szegedy等人引入的Inception架构(Inception-v1)[37],后来被细化为Incepiton-v2[38]、Inception-v3[39],最近又被简化为Inception-ResNet[6],是ImageNet数据集中表现最好的模型家族之一。受这些模式在ImageNet竞赛中的成功启发,我们在CNN网络中合并了改良版的Inception-ResNet-A。
3.4描述我们的网络架构。
本研究的神经网络设计如图3所示。网络的第一层是7×7的卷积层,紧随其后是大小为3×3,步长为2的池化层。卷积层用7×7的卷积核在输入图像的3通道(RGB)上获得64个特征图。这将压缩网络中的信息。缩小图像的维数以便减少计算时间,并且使得模型更加适应GPU的内存[41]。同样,为了降低特征图的维度,在卷积核大小为5×5的卷积层之前用了一个卷积核大小为1×1的卷积层。
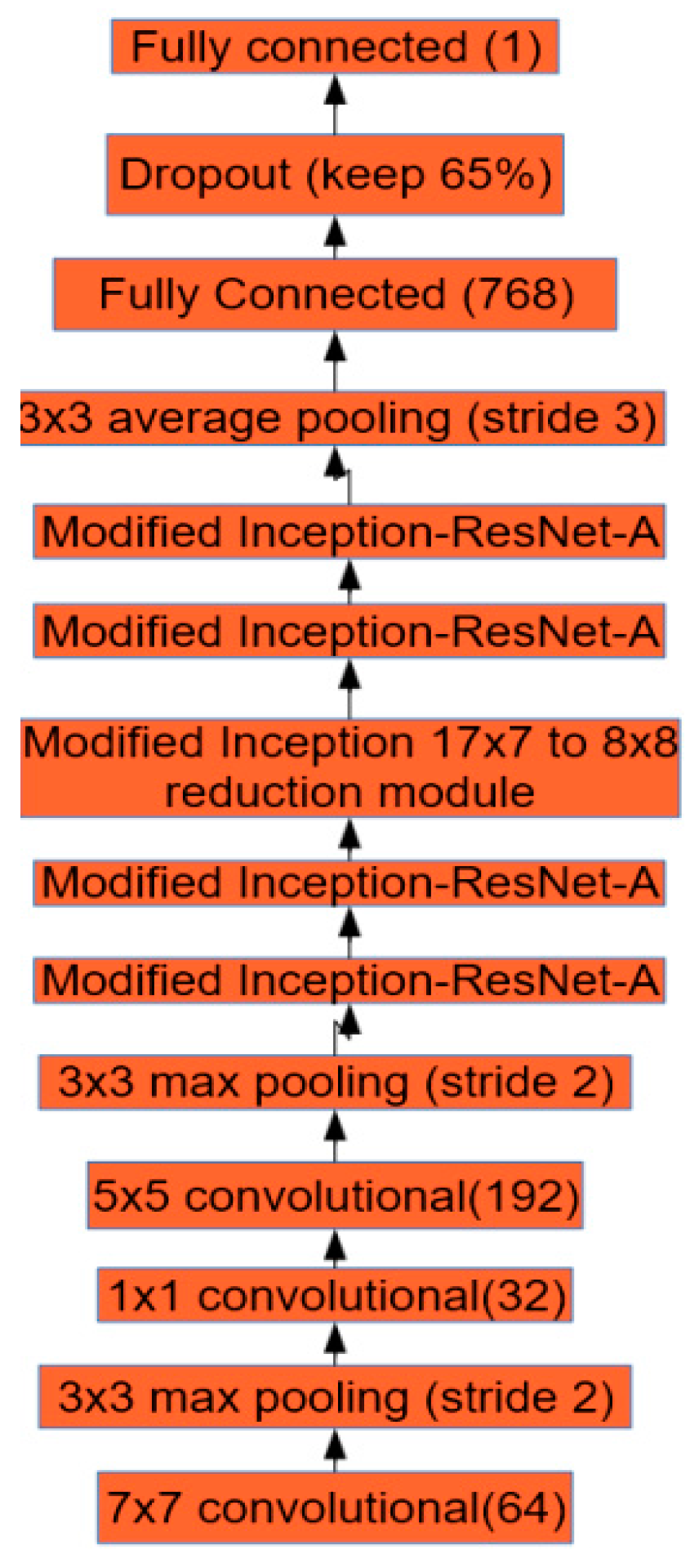 图3 我们的网络架构
图像中对象的大小各不相同,因此需要一种能够在多个尺度上捕获特征的体系结构。为此,我们修改了inperception - resnet - a[6]层。为此,我们修改了Inception-ResNet-A[6]层。在正则化卷积层后面跟着两个改进的Inception-ResNet-A层,它通过连接不同内核大小的卷积层的结果来捕获不同大小的特性,以及使用跳过连接创建信息在神经网络中流动的简单路径的剩余网络[3]。该体系结构之所以被使用,是因为它在[6]上的几个竞争图像识别挑战中表现出色。在深度网络[3]中,由于残端连接加快了训练速度,所以残端网络收敛得更快。图4显示了在此工作中使用的修改后的输入- resnet模块的设计。最后1×1只卷积计算192的特性,而256年原Inception-ResNet-A[6]。
Inception-ResNet结合了Inception的思想,它通过将不同卷积核大小的卷积层的结果和残差网络的结果连接起来,从而获取不同大小的特征,而残差网络则使用跳过连接(skip connections)来创建一个简单的路径,使信息在整个神经网络中流动。
之所以用这种体系结构,是因为它在一些图像识别竞赛中表现出色[6]。由于残差连接加快了深度网络的训练,残差网络收敛速度更快。图4显示了在本研究中使用的改良的Inception-ResNet-A模块。相比于原始的Inception-ResNet-A模块中的256个特征,最终的1×1卷积仅计算出192个特征。
图3 我们的网络架构
图像中对象的大小各不相同,因此需要一种能够在多个尺度上捕获特征的体系结构。为此,我们修改了inperception - resnet - a[6]层。为此,我们修改了Inception-ResNet-A[6]层。在正则化卷积层后面跟着两个改进的Inception-ResNet-A层,它通过连接不同内核大小的卷积层的结果来捕获不同大小的特性,以及使用跳过连接创建信息在神经网络中流动的简单路径的剩余网络[3]。该体系结构之所以被使用,是因为它在[6]上的几个竞争图像识别挑战中表现出色。在深度网络[3]中,由于残端连接加快了训练速度,所以残端网络收敛得更快。图4显示了在此工作中使用的修改后的输入- resnet模块的设计。最后1×1只卷积计算192的特性,而256年原Inception-ResNet-A[6]。
Inception-ResNet结合了Inception的思想,它通过将不同卷积核大小的卷积层的结果和残差网络的结果连接起来,从而获取不同大小的特征,而残差网络则使用跳过连接(skip connections)来创建一个简单的路径,使信息在整个神经网络中流动。
之所以用这种体系结构,是因为它在一些图像识别竞赛中表现出色[6]。由于残差连接加快了深度网络的训练,残差网络收敛速度更快。图4显示了在本研究中使用的改良的Inception-ResNet-A模块。相比于原始的Inception-ResNet-A模块中的256个特征,最终的1×1卷积仅计算出192个特征。
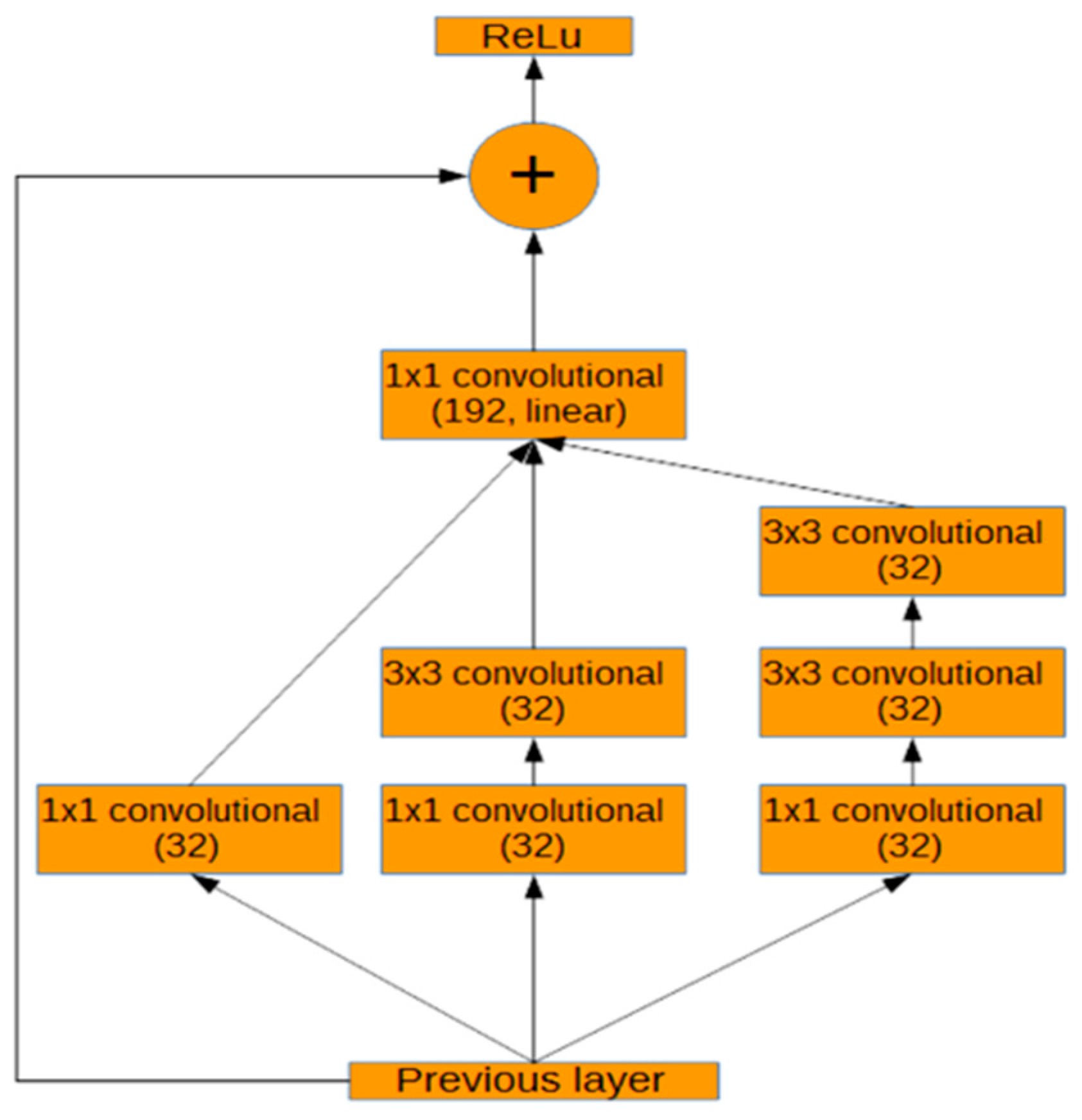 图4 改良的Inception-ResNet-A模块
如图4所示,改良后的Inception-ResNet-A模块由连接在一起的三个并行层级联而成。然后将这个连接的结果添加到前一层的激活中,并通过修正线性函数。在改良的Inception-ResNet-A层之后,将使用一个改良的Inception的reduction模块。如图5所示,以同时减少图像大小和增加过滤器的数量。
如图5所示,三个并行分支被连接到一个输出。这些分支包括最大池化和跨越无填充卷积(图5中的stride 2v)。模块的中间分支从输出大小192减少到128。模块的右分支分别从256、256、320和320减小到192、128和128。这些改变是为了使网络更贴近问题的复杂性。在这些修改之前,模型往往过于拟合训练数据,而在真实数据上表现得很差。
图4 改良的Inception-ResNet-A模块
如图4所示,改良后的Inception-ResNet-A模块由连接在一起的三个并行层级联而成。然后将这个连接的结果添加到前一层的激活中,并通过修正线性函数。在改良的Inception-ResNet-A层之后,将使用一个改良的Inception的reduction模块。如图5所示,以同时减少图像大小和增加过滤器的数量。
如图5所示,三个并行分支被连接到一个输出。这些分支包括最大池化和跨越无填充卷积(图5中的stride 2v)。模块的中间分支从输出大小192减少到128。模块的右分支分别从256、256、320和320减小到192、128和128。这些改变是为了使网络更贴近问题的复杂性。在这些修改之前,模型往往过于拟合训练数据,而在真实数据上表现得很差。
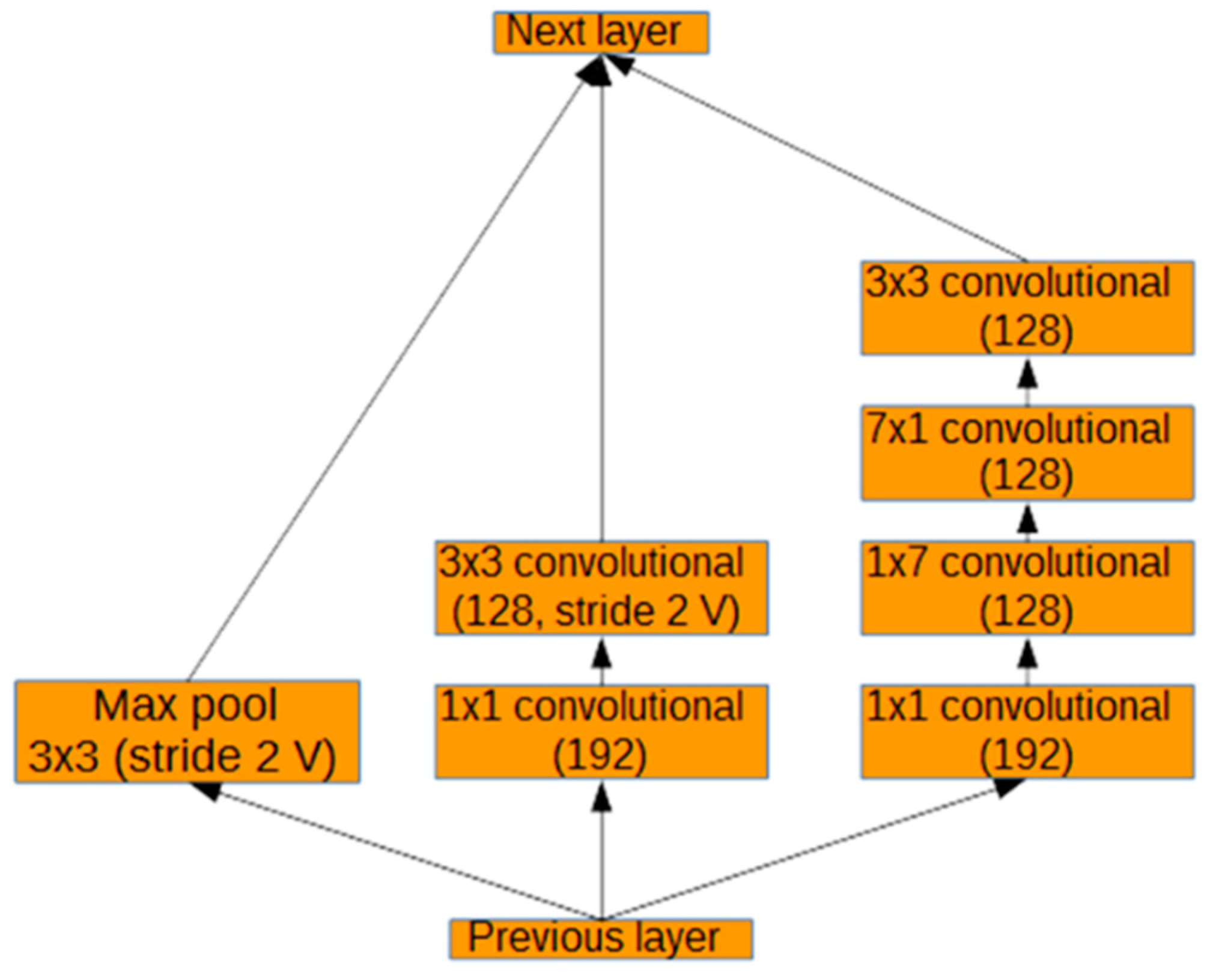 图5 改良的reduction模块
改良了reduction模块之后,又用了另一组两个Inception-ResNet-A层,接着是3×3平均池化,因为平均池化被发现用在最后的全连接层之前可以提高精度[42]。如图3所示,最终全连接层的大小为768。虽然具有大量参数的深度神经网络是非常强大的机器学习系统,但过拟合是此类网络中的一个严重问题。大型网络的使用速度也较慢,通过在测试时结合许多不同的大型神经网络的预测,很难处理过拟合。Dropout是解决这个问题的一种技巧。关键的技巧是在训练时从神经网络中随机删除神经元(以及它们的连接)。65%的连接是在网络训练时随机保留的。最后,在dropout层之后的最后一个全连接层给出输入图像中西红柿数量的预测。每次卷积后进行BN批量归一化以解决Internal Covariate Shift的问题[38]。
(译者注: 在深度网络的训练中,每一层网络的输入都会因为前一层网络参数的变化导致其分布发生改变,这就要求我们必须使用一个很小的学习率和对参数很好的初始化,但是这么做会让训练过程变得慢而且复杂。作者把这种现象称作Internal Covariate Shift。通过Batch Normalization可以很好的解决这个问题,并且文中提出的这种Batch Normalization方法前提是用mini-banch来训练神经网络。)
图5 改良的reduction模块
改良了reduction模块之后,又用了另一组两个Inception-ResNet-A层,接着是3×3平均池化,因为平均池化被发现用在最后的全连接层之前可以提高精度[42]。如图3所示,最终全连接层的大小为768。虽然具有大量参数的深度神经网络是非常强大的机器学习系统,但过拟合是此类网络中的一个严重问题。大型网络的使用速度也较慢,通过在测试时结合许多不同的大型神经网络的预测,很难处理过拟合。Dropout是解决这个问题的一种技巧。关键的技巧是在训练时从神经网络中随机删除神经元(以及它们的连接)。65%的连接是在网络训练时随机保留的。最后,在dropout层之后的最后一个全连接层给出输入图像中西红柿数量的预测。每次卷积后进行BN批量归一化以解决Internal Covariate Shift的问题[38]。
(译者注: 在深度网络的训练中,每一层网络的输入都会因为前一层网络参数的变化导致其分布发生改变,这就要求我们必须使用一个很小的学习率和对参数很好的初始化,但是这么做会让训练过程变得慢而且复杂。作者把这种现象称作Internal Covariate Shift。通过Batch Normalization可以很好的解决这个问题,并且文中提出的这种Batch Normalization方法前提是用mini-banch来训练神经网络。)
3.5训练方法
该网络在24000幅合成图像上进行了3个epoch的训练。为了最小化错误,使用了一个Adam优化器[44]。这是一种基于低阶矩自适应估计的一阶随机梯度优化目标函数的算法。 受到AdaGrad和RMSProp这两种流行的优化方法的启发,Kingma和Ba[44]提出了一种新的优化器,可以处理稀疏梯度以及非平稳目标。使用Adam优化器的优点包括:计算效率高、内存需求低、不变性、对角线重调,以及非常适合处理数据或参数较大的问题。Adam优化器的学习速率是一个常数1×10−3。均值平方误差作为代价函数。 利用加权指数移动平均权值对网络进行评估。使用Xavier初始化器[45]初始化权重。Xavier初始化通过在整个层中保持信号在一个合理的值范围来确保权重是合适的。它保持输入梯度和输出梯度的方差不变,这有助于在整个网络中保持梯度的尺度大致相同。
4实验结果
该网络使用TensorFlow[46]实现并运行在NVidia 980Ti GPU上。使用了24,000个合成图像去训练。为了进行测试,我们使用了一组来自谷歌图像的2400张合成图像和100张随机选择的真实西红柿图像。合成图像的大小为128×128像素。真实图像大小不同,但都统一调整大小为128×128像素。
4.1 在合成数据上的实验结果
对2400幅合成图像的验证得出了大约1.16的平均值平方误差。图6显示了训练的平均值平方误差,横坐标表示步数,纵坐标表示均方误差。对网络进行三种不同的dropout值(50%、65%和80%)的训练,找出均值平方误差的最小值,选择65%作为网络的dropout值。图6显示了dropout为65%的均值平方误差。从图6中可以看出,网络收敛速度很快;这就是为什么网络只训练了三个epoch。
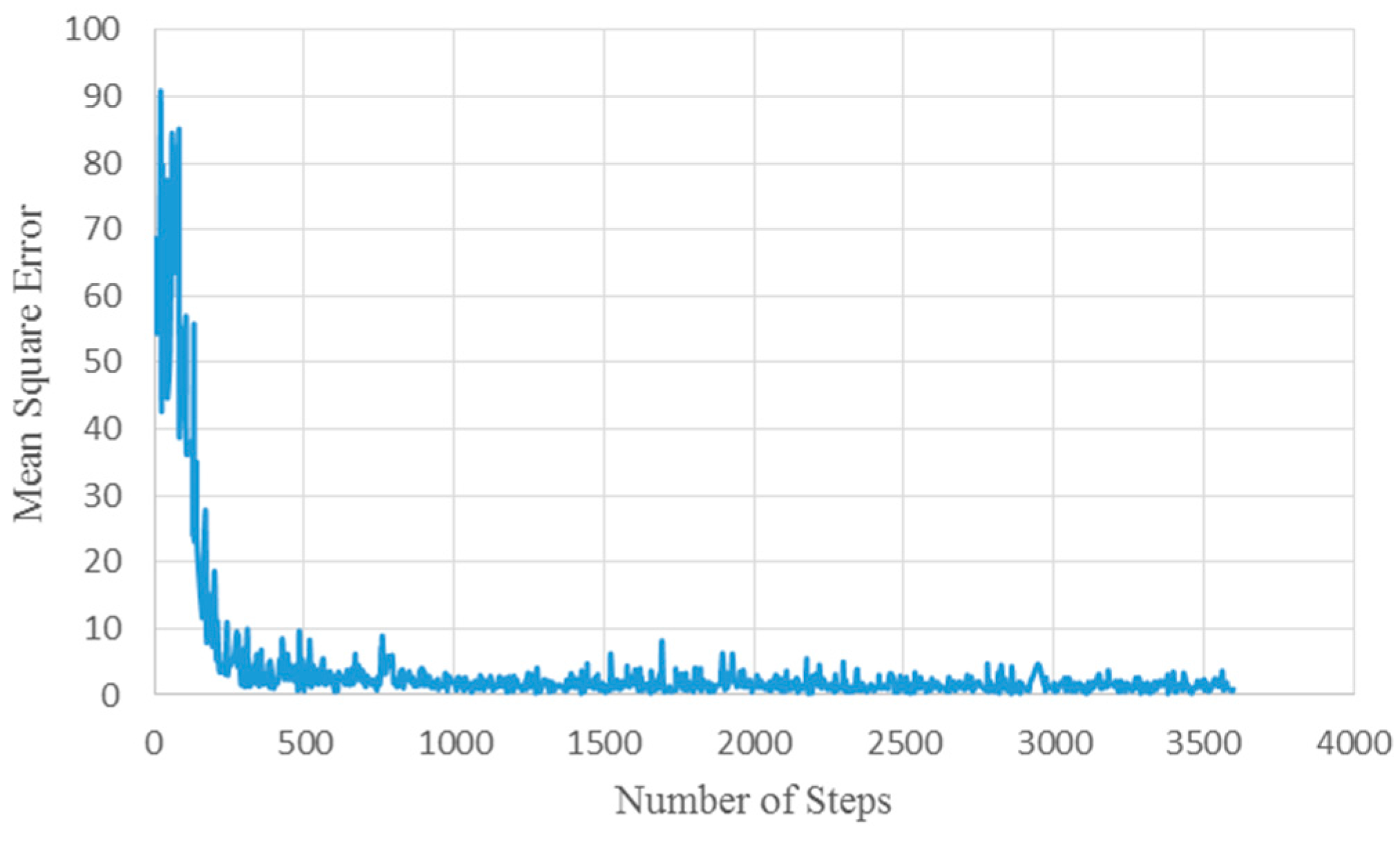 图6 训练的均方误差为65%
图6 训练的均方误差为65%
4.2在真实数据上的实验结果
该算法对100多幅随机选择的图像进行了测试;尽管没有用的真实图像进行训练,但网络对真实图像表现良好。表1显示了20幅具有代表性的图像及其预测和实际计数。在表1列R包含真实图像,列P包含预测值,列GT包含实际计数(ground truth)。
 表1 真实西红柿图像的预测(P)和实际计数(GT)
这个网络被训练用来计算熟西红柿和半熟西红柿。该算法可以处理光照、大小、阴影等方面的变化,也可以处理重叠部分遮挡的图像。例如,第二行第四列图像中的果实部分被叶子遮挡,同时有不同的光照条件。然而,我们的算法的实际计数和预测计数完全相同(=12)。另一个例子是最后一行最后一列的图像,它重叠了不同大小的果实,被树叶遮挡;尽管如此,我们的算法的实际计数和预测计数是完全相同的(=24)。
表1 真实西红柿图像的预测(P)和实际计数(GT)
这个网络被训练用来计算熟西红柿和半熟西红柿。该算法可以处理光照、大小、阴影等方面的变化,也可以处理重叠部分遮挡的图像。例如,第二行第四列图像中的果实部分被叶子遮挡,同时有不同的光照条件。然而,我们的算法的实际计数和预测计数完全相同(=12)。另一个例子是最后一行最后一列的图像,它重叠了不同大小的果实,被树叶遮挡;尽管如此,我们的算法的实际计数和预测计数是完全相同的(=24)。
4.3结果评估
为了评估结果的性能,我们将算法的预测值与实际计数进行了比较。实际计数是通过三个独立观察图像的人的平均计数得到的。精度计算如下:
(1)
式中,pa为精度(%),pc为预测计数,ac为实际计数。如图7所示,准确率在70% ~ 100%之间,100幅图像的平均准确率为91.03%。
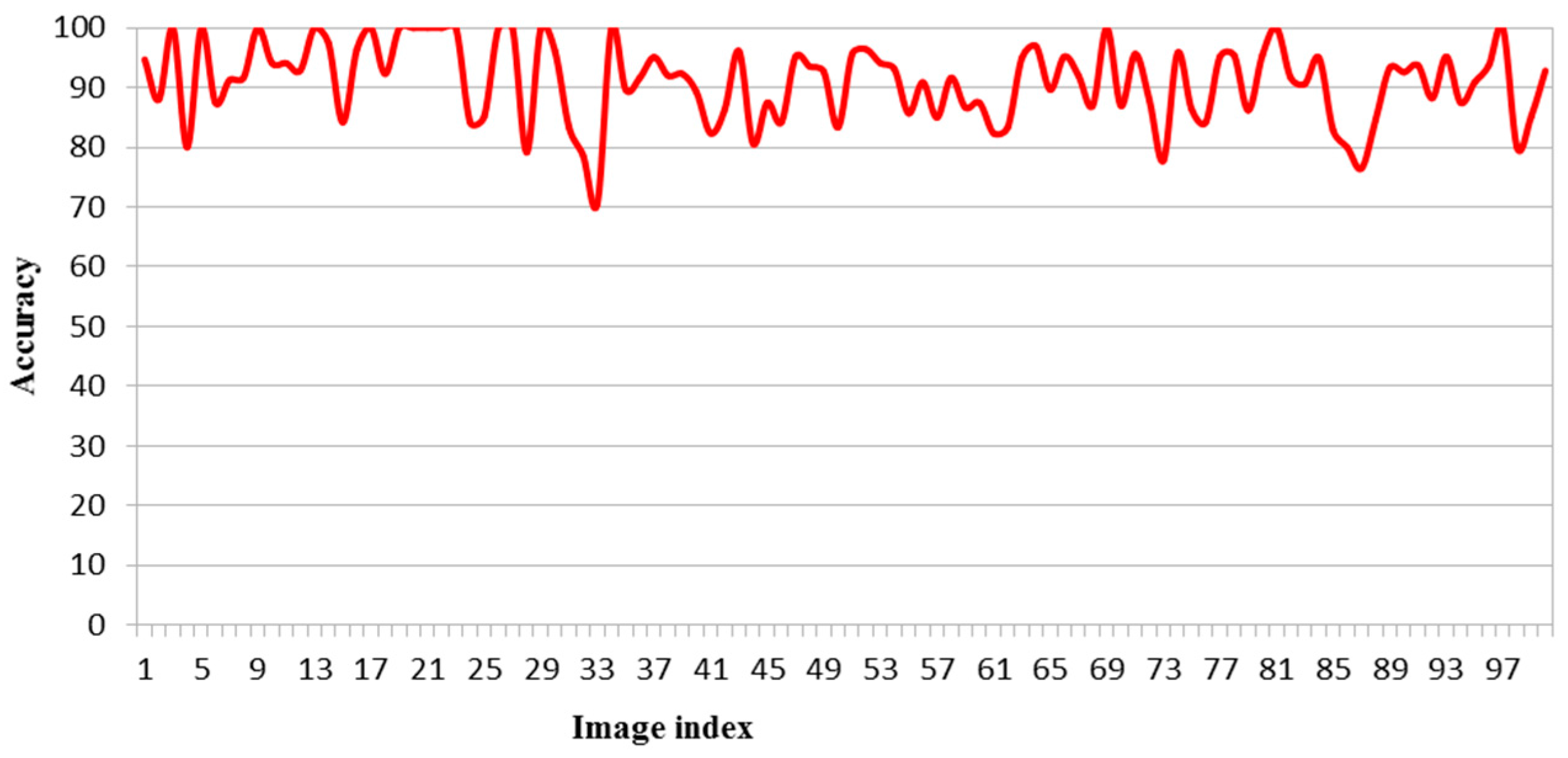 图7 100张图片的精确度
在计算和实际计数之间进行线性回归,如图8所示。图8中R2值为0.90,表明回归线与数据拟合较好,这意味着西红柿的计算计数与实际计数相似。2400幅合成图像的均方根误差(RMSE)为1.16,100幅真实图像的均方根误差为2.52。
图7 100张图片的精确度
在计算和实际计数之间进行线性回归,如图8所示。图8中R2值为0.90,表明回归线与数据拟合较好,这意味着西红柿的计算计数与实际计数相似。2400幅合成图像的均方根误差(RMSE)为1.16,100幅真实图像的均方根误差为2.52。
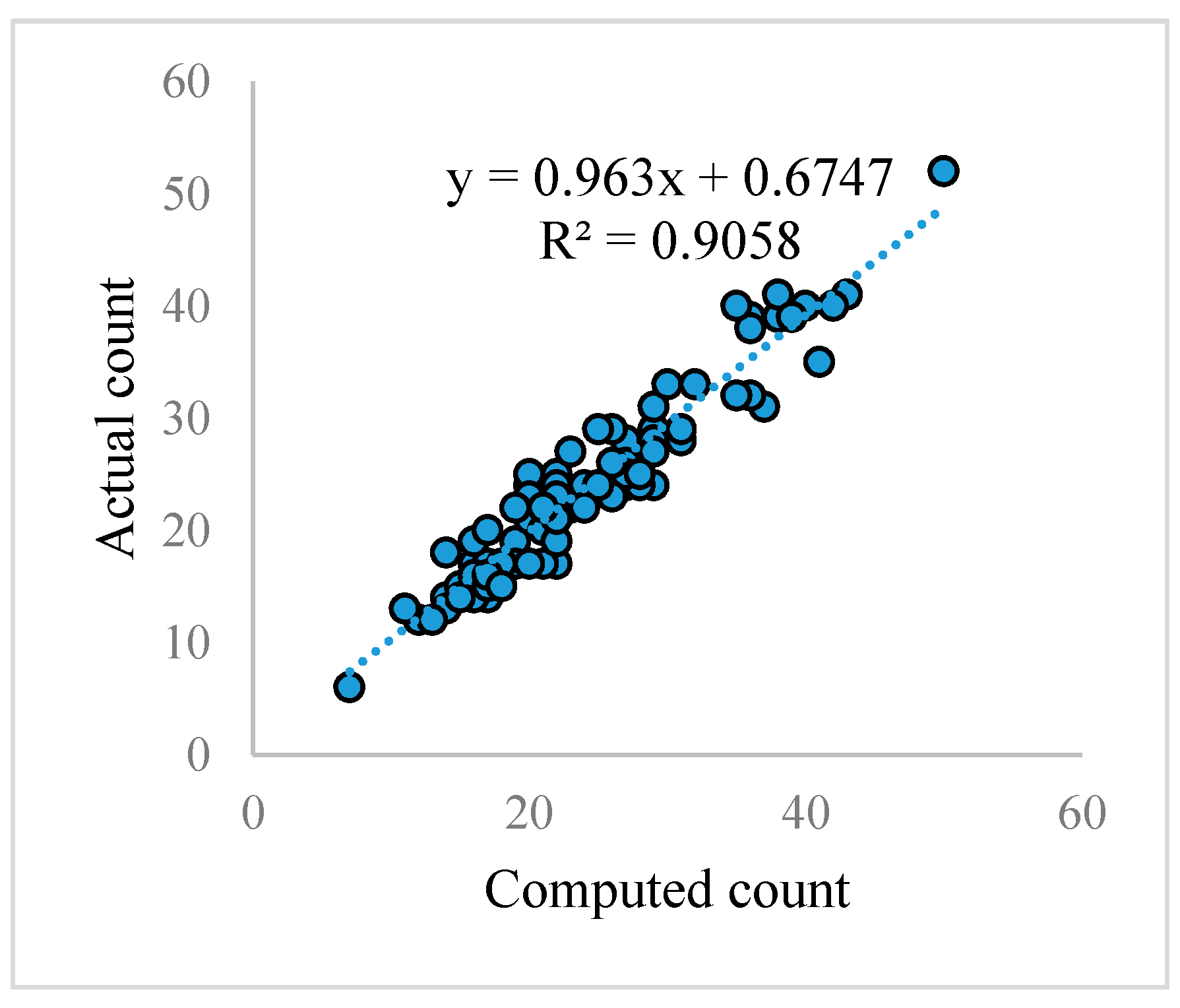 图8 对100张真实的西红柿图像进行计算和实际计数之间的线性回归
图8 对100张真实的西红柿图像进行计算和实际计数之间的线性回归
4.4与其他技术相比
我们将我们的结果与几种方法进行了比较,即基于区域的技术、浅层神经网络以及我们的网络与原始的感知神经网络。
基于区域的技术根据的总面积和单个计算的数量。在将RGB图像转换为YCBCR空间后,我们应用了数学形态学技术来分离属于西红柿的像素。在计算每幅图像中的总像素后,我们将其除以一个西红柿的平均像素覆盖率来得到计数。实验得到了每个西红柿的平均像素数,使实际计数与基于面积的计算计数之间存在最小距离。这个方法的平均精度超过100个图像,为66.16%。图9显示了基于面积法的计算计数与100幅真实西红柿图像的实际计数之间的线性回归。基于该方法的100幅真实图像的RMSE为13.56。
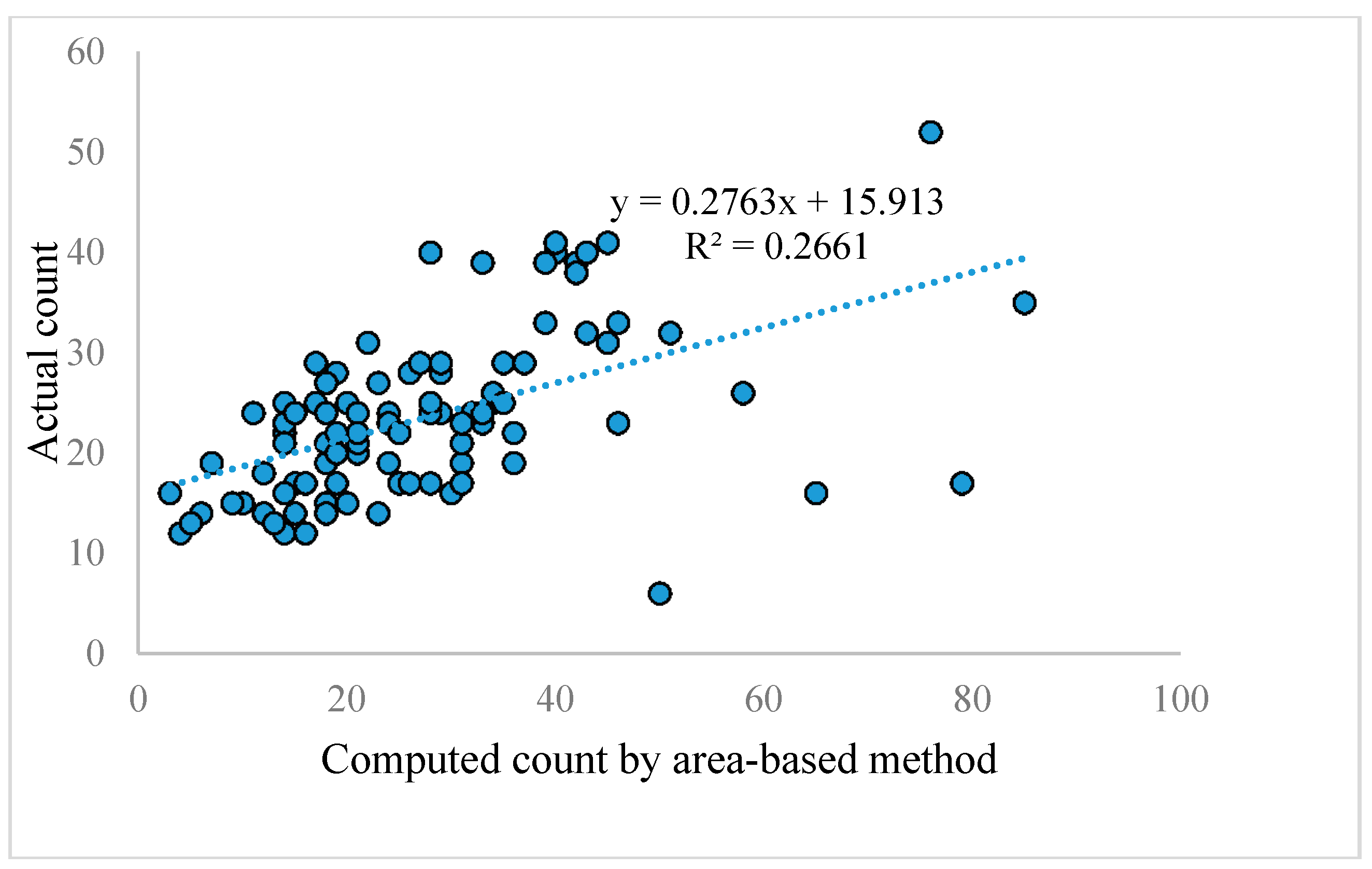 图9 基于区域的方法计算的计数与100张真实西红柿图像的实际计数之间的线性回归
从图9可以推断,该方法的性能不一致,R2值也很差。我们也在一个浅的网络上训练和测试结果。浅层网络由两个卷积层和两个全连通层组成。在第三种方法中,我们使用了原始的Inception-ResNet-A模块的Inception-ResNet-v4层,而不是我们在图4中修改的版本。表2显示了使用所提方法和其他三种方法的100幅以上图像的平均准确率。
图9 基于区域的方法计算的计数与100张真实西红柿图像的实际计数之间的线性回归
从图9可以推断,该方法的性能不一致,R2值也很差。我们也在一个浅的网络上训练和测试结果。浅层网络由两个卷积层和两个全连通层组成。在第三种方法中,我们使用了原始的Inception-ResNet-A模块的Inception-ResNet-v4层,而不是我们在图4中修改的版本。表2显示了使用所提方法和其他三种方法的100幅以上图像的平均准确率。
 表2 超过100幅图像的平均精度
从表2可以看出,所提出的方法明显优于基于区域的方法。原因是基于区域的方法不具有尺度不变性。此外,基于区域的方法的主要问题是,当其他西红柿、树叶或枝条遮挡时,西红柿的总像素覆盖率将小于实际覆盖率,从而导致对西红柿的错误计数。
表3显示了使用所提出的方法、基于区域的方法在一个测试图像中计数西红柿所需的平均时间,以及人类手工计数所需的时间。
表2 超过100幅图像的平均精度
从表2可以看出,所提出的方法明显优于基于区域的方法。原因是基于区域的方法不具有尺度不变性。此外,基于区域的方法的主要问题是,当其他西红柿、树叶或枝条遮挡时,西红柿的总像素覆盖率将小于实际覆盖率,从而导致对西红柿的错误计数。
表3显示了使用所提出的方法、基于区域的方法在一个测试图像中计数西红柿所需的平均时间,以及人类手工计数所需的时间。
 表3 计数的平均时间
表3显示,所提出的方法比基于区域和手工计数的方法要快。
表3 计数的平均时间
表3显示,所提出的方法比基于区域和手工计数的方法要快。
5 结论与展望
我们提出模拟学习来计算果实。我们的体系结构建立在Inception-ResNet的基础上,以达到高精度和降低计数成本。在深度学习的训练阶段,很难获得足够的真实图像以及这些图像中果实的实际数量;在本文中,我们生成了西红柿的合成图像用于网络训练。我们观察了100幅随机选择的真实图像具有91%的准确率。我们的算法在恶劣条件下是健壮的。它可以精确地计数,即使西红柿在阴影下,被树叶、树枝遮挡,或有一定程度的重叠。虽然我们的算法是训练用来数西红柿的,但它也可以应用于其他果实。我们的算法可以计算熟和半熟的;然而,它没有计算绿色果实,因为它没有为此目的进行训练。在未来,我们计划将绿色果实添加到合成数据集中,这样它就可以对果实的各个阶段进行计数。 未来,我们计划开发一种基于该算法的移动应用,该算法可直接供农民进行产量估算和栽培实践。此外,该算法将在无人地面车辆(UGVs)和空中无人机(uav)上实现,用于在线产量估计和精准的农业应用。
鸣谢
这个项目得到了德州农工大学-科珀斯克里斯蒂研究、商业化和外联部以及德州农工大学-科珀斯克里斯蒂研究增强基金的部分支持。
作者的贡献
Rahnemoonfar和Sheppard设计了实验;谢泼德进行实验;拉恩莫法负责监督整个项目。两位作者分析了数据并撰写了论文。
利益冲突
作者声明没有利益冲突。
参考文献
见原文:Deep Count: Fruit Counting Based on Deep Simulated Learning